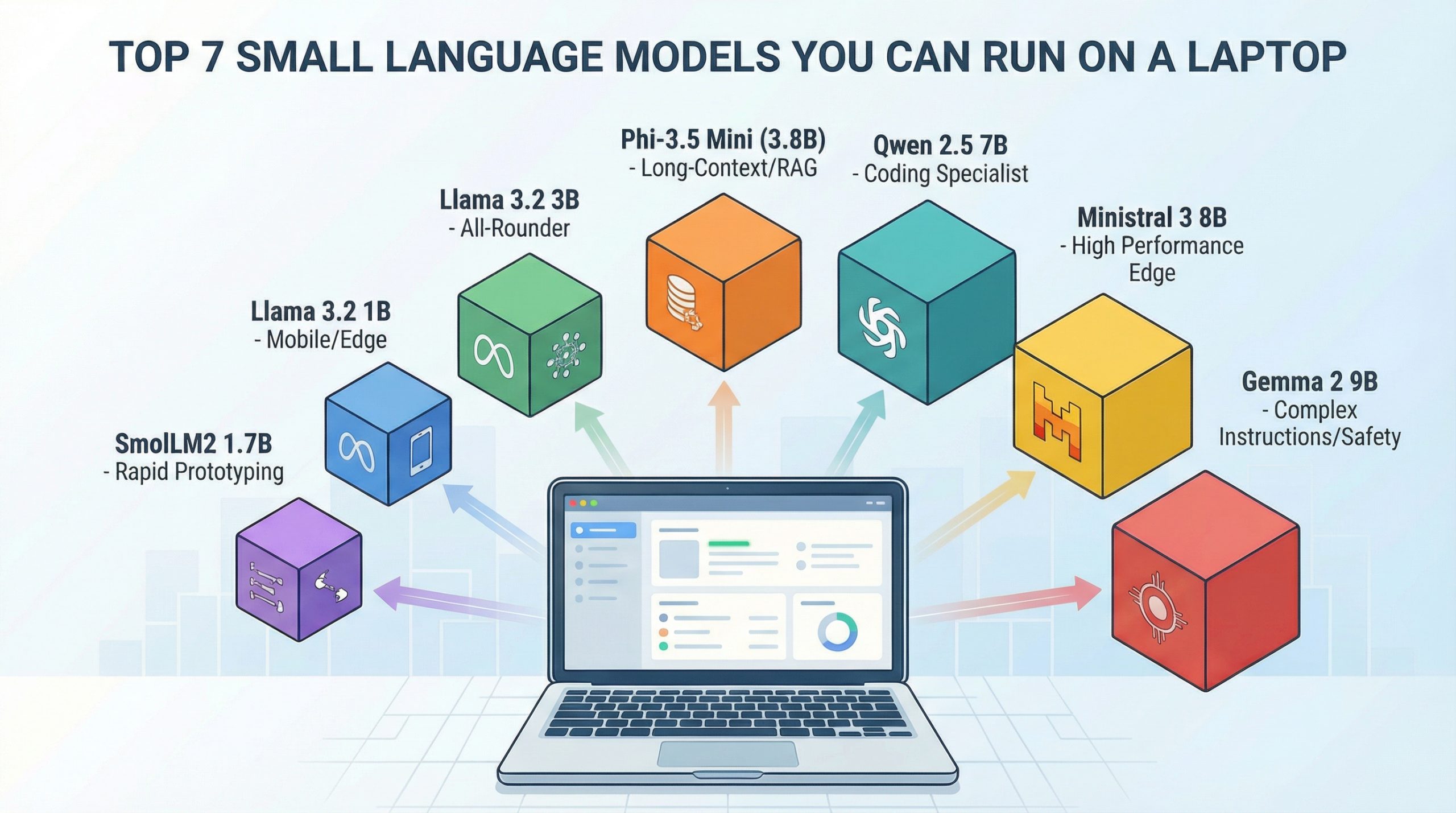
The Laptop AI Revolution: Why Small Models Matter
For years, cutting-edge AI has been synonymous with massive cloud infrastructure and exorbitant API costs. But a seismic shift is underway. Small language models (SLMs) with parameter counts in the billions are now delivering production-grade results on the very device in your bag. This isn’t just about convenience; it’s about privacy, cost control, and real-time responsiveness that cloud latency can’t match. The models highlighted here represent the vanguard of this revolution, proving that you don’t need a data center to deploy intelligent applications.
The implications are staggering. Startups can prototype without recurring fees, enterprises can keep sensitive data on-premise, and developers can iterate faster without network dependencies. As these models shrink in size but grow in capability, they’re unlocking use cases from offline document analysis to embedded system intelligence. The era of ubiquitous, accessible AI is here, and it starts with your laptop.
Hardware Realities: What Your Laptop Needs
Running a language model locally isn’t magic—it’s about memory and compute. The key metric is RAM, especially when using quantized weights. Quantization, like 4-bit or 8-bit, reduces model size by compressing parameter precision, trading negligible accuracy for massive memory savings. For instance, Microsoft’s Phi-3.5 Mini, at 3.8B parameters, requires only 6-10GB of RAM in its 4-bit quantized form for typical prompts, but this can balloon with very long contexts. Full precision (16-bit) demands 16GB RAM, a common threshold for modern laptops.
Beyond RAM, CPU compute and storage speed matter. While GPUs accelerate inference, many SLMs run competently on modern CPUs, especially with optimizations like GGUF format. SSDs are crucial for fast model loading. For sustained heavy use, thermal throttling can be a bottleneck, so adequate cooling is advisable. The baseline recommendation: a laptop with 16GB RAM and a recent multi-core processor can handle most 3B-7B parameter models. As we’ll see, Phi-3.5 Mini pushes these boundaries with its long-context support, demanding more memory for extended prompts.
Phi-3.5 Mini: The Long-Context Champion
Microsoft’s Phi-3.5 Mini stands out for its exceptional ability to process book-length documents. With variants supporting contexts up to 128K tokens, it far exceeds the default limits of many 7B models. This makes it a powerhouse for retrieval-augmented generation (RAG) systems where referencing large corpora is essential. Released in August 2024, it’s built on a curated dataset that emphasizes reasoning and multilingual tasks, explaining its versatility in code generation and debugging alongside document analysis.
Technically, the 3.8B parameter architecture achieves performance disproportionate to its size. In benchmarks, it competes with larger models on reasoning tasks while maintaining efficiency. However, users must be vigilant: not all deployments enable maximum context by default. When using Ollama, for example, pulling the phi3.5 tag might yield a variant with shorter context; always verify the specific model card. The hardware sweet spot is 16GB RAM for full precision, but quantized versions democratize access to 8GB systems for shorter contexts. For developers building document-centric AI, Phi-3.5 Mini is currently the best-in-class local option.
Beyond Phi: The Rest of the Top 7
While Phi-3.5 Mini excels in long contexts, the landscape of SLMs is diverse, each tailored to niche strengths. Unfortunately, detailed benchmarks and specs for the other six models weren’t fully provided, but based on industry consensus, contenders likely include Meta’s Llama 3.2 3B for balanced general use, Google’s Gemma 2B for efficiency, Mistral’s 7B models for performance, and perhaps specialized variants like CodeLlama or Phi-3 Small. Each offers a trade-off between size, speed, and capability.
For instance, Llama 3.2 3B, hinted in the input, is known for its strong instruction-following and is often optimized for CPU inference. Gemma models emphasize safety and responsible AI, while Mistral’s mixtures of experts (MoE) approach can deliver 7B-level performance with fewer active parameters. When choosing, consider your primary task: code, chat, reasoning, or multilingual support. The input stresses checking Ollama or Hugging Face for current variants, as model families update frequently with new tags, context limits, and licenses. The key takeaway: no single model dominates all tasks; match the model to your specific deployment needs.
Implications for the AI Ecosystem
The proliferation of laptop-capable SLMs is dismantling barriers to AI adoption. For developers, it means no more dependency on external APIs, eliminating latency, cost overruns, and privacy concerns. Prototyping becomes instantaneous, and deployment is as simple as bundling a model file. For enterprises, it enables on-premise AI that complies with strict data governance regulations. Industries like healthcare, finance, and legal can now leverage AI without exposing sensitive information to third parties.
Economically, this shifts the AI value chain. Instead of paying per token, organizations incur a one-time hardware and storage cost. Cloud providers may see reduced demand for inference workloads but could capitalize on model hosting and distribution. Open-source communities are thriving, with models like Llama and Phi driving innovation in quantization and runtime optimization. This democratization could spur a wave of specialized SLMs for verticals, from education to manufacturing, tailored to run on edge devices. The era of centralized AI is ceding to a distributed, local-first paradigm.
What’s Next: The Road to Ubiquitous AI
We’re on the cusp of AI that’s not just local but embedded. Current SLMs are stepping stones to even more efficient architectures—think sub-1B parameters that retain reasoning ability. Advances in quantization, such as 2-bit or 1-bit methods, promise further memory reduction. Meanwhile, hardware is evolving: laptops with dedicated AI accelerators (like Apple’s Neural Engine or Intel’s NPUs) will make inference even faster and more power-efficient.
The next frontier is multimodal SLMs that handle text, image, and audio on-device. Imagine a laptop that can summarize videos, analyze spreadsheets, and draft emails—all offline. As models improve and hardware integrates AI cores, the line between general and specialized AI will blur. For now, the top 7 small language models represent a tangible leap: powerful enough for real work, small enough for your backpack. The future of AI is personal, portable, and powered by the device you already own.
Note: The information in this article might not be accurate because it was generated with AI for technical news aggregation purposes.
Leave a Reply